The Ultimate Search Engine Spider Simulator Guide for SEO

Master SEO with a Search Engine Spider Simulator
Introduction
Peek behind the digital curtain of the web.
A search engine spider simulator is a powerful tool that emulates how search engine crawlers, like the famous Googlebot, navigate and interpret your website. It strips away the user-facing design to show you what a bot really sees: the raw code, the text, the links, and the directives that determine your site's fate in search results. It’s your X-ray vision for technical SEO.
## The Unseen Architects: What Exactly is a Search Engine Spider?
Before we can simulate the spider, we have to understand the beast itself. You've probably heard terms like "bots," "crawlers," or "spiders" thrown around. They all refer to the same thing: automated programs that systematically browse the internet. Their primary mission? To discover, scan, and index web pages to be added to the vast library of the search engine, like Google or Bing. Without these tireless digital workers, search engines would be empty, useless portals. They are the foundation upon which all of online search is built.
These aren't malicious entities; they are the information gatherers. They follow links from one page to another, creating a massive, interconnected map of the web. This map, known as the search index, is what Google consults when you type in a query. The spider's job is to ensure this map is as accurate, comprehensive, and up-to-date as possible. Understanding their behavior is the first, and arguably most crucial, step in mastering search engine optimization. If a spider can't understand your site, it simply won't rank.
### The Digital Librarians of the Internet
Think of the entire internet as a colossal, ever-expanding library with no central catalog. Now, imagine a team of hyper-efficient librarians (the spiders) tasked with reading every single book (web page), understanding its content, and noting how it connects to other books (links). This is precisely what search engine spiders do. They don't just read the title; they analyze the table of contents (headings), the chapters (content), the footnotes (links), and even the publishing information (metadata). They are meticulous to a fault.
These digital librarians don't get tired. They work 24/7, constantly revisiting pages to check for updates, discovering new ones, and noting when old ones have been removed. Their work allows the head librarian (the search engine algorithm) to instantly find the most relevant books for any given topic a user requests. When you use a SEARCH ENGINE SPIDER SIMULATOR, you're essentially borrowing one of these librarian's special glasses to see the library's structure exactly as they do. This perspective is invaluable because it reveals the hidden architecture that users never see but which entirely dictates your visibility. It's about looking at the shelves, not just the book covers.
### Googlebot, Bingbot, and Friends: A Cast of Crawlers
While Googlebot is the undisputed celebrity in the world of web crawlers, it's certainly not the only one on the stage. Every major search engine deploys its own fleet of spiders. Microsoft has Bingbot, which powers the Bing search engine. DuckDuckGo utilizes its own crawler, DuckDuckBot, in addition to sourcing results from other places. Yandex, a major search engine in Russia, has YandexBot. Each of these crawlers has slightly different "personalities" and behaviors, although they all share the same fundamental purpose.
For instance, they might have different crawl rates or prioritize different types of content. Some might be more aggressive in how they handle JavaScript. This is why a sophisticated spider simulator often allows you to switch the "user-agent"—the digital signature that tells a website which bot is visiting. You can choose to see your site as Googlebot-Desktop, Googlebot-Mobile (incredibly important for mobile-first indexing), or even Bingbot. Understanding that you're catering to a diverse cast of crawlers, not just Google's, can give you a competitive edge, ensuring your site is universally accessible and optimized for every potential source of traffic.
## A New Perspective: Introducing the Search Engine Spider Simulator
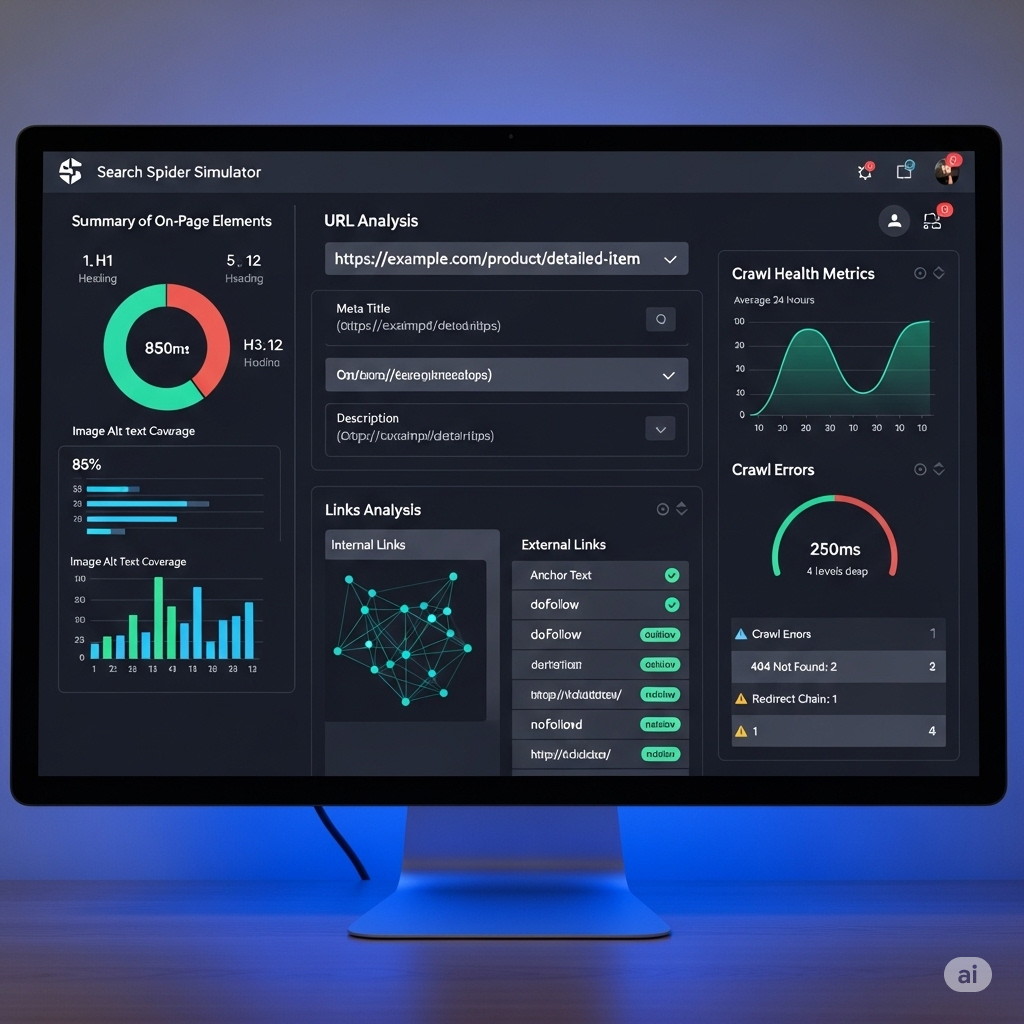
Now that we appreciate the spiders, let's talk about the simulator. At its core, a spider simulator is a diagnostic tool. It's a piece of software, either web-based or desktop, that you point at your website's URL. Instead of rendering the page with beautiful CSS and interactive JavaScript like a normal browser, it fetches the page like a search engine bot would. It follows the links it finds, records the HTTP status codes, extracts the text content, and parses the crucial HTML tags. The result is a raw, unfiltered view of your website's technical foundation.
This process peels back the layers of design and user experience to reveal the skeleton underneath. You get to see the messy reality of your code, the structure of your internal links, and any roadblocks that might be stopping a real spider in its tracks. It's the equivalent of an architect reviewing the blueprints of a building instead of just looking at the finished structure. The simulator shows you the load-bearing walls, the electrical wiring, and the plumbing—the critical infrastructure that must be sound for the building to stand tall.
### A Window into the Crawler's World
Imagine trying to guide someone through a complex maze, but you're blindfolded. That's what doing SEO without understanding crawlability is like. A web crawler emulator effectively removes that blindfold. It provides a clear, unvarnished window into how a bot experiences your digital property. Does the bot see that critical piece of text you spent hours writing, or is it hidden behind some fancy JavaScript that the bot can't (or won't) execute properly? Are your navigation links clear and followable, or are they a tangled mess of broken redirects?
This "window" shows you exactly what text a spider can extract from your page. It highlights your <h1> tags, your meta descriptions, and your image alt text. It flags pages that return a 404 Not Found error, which are dead ends for a crawler. It shows you chains of redirects (301 -> 301 -> 200) that waste precious crawl resources. By looking through this window, you stop guessing. You move from assumption to data-driven diagnosis. You're no longer just hoping that Google understands your site; you're actively verifying it.
### Why You Can't Just Rely on Your Browser
"But my website looks fine in Chrome/Firefox/Safari! Why do I need a special tool?" This is a common and dangerous misconception. Modern web browsers are incredibly sophisticated pieces of software designed for one purpose: to create the best possible experience for a human user. They are built to be lenient. They will work tirelessly to render a page, even if the underlying code is a complete mess. They execute complex JavaScript, interpret convoluted CSS, and try to make sense of broken HTML. A browser's job is to hide imperfections.
A search engine spider, on the other hand, has a different job. Its primary goal is efficiency and data extraction at a massive scale. While Googlebot has gotten much better at rendering JavaScript, it's not the same as a user's browser. It operates on a budget—a "crawl budget"—and won't waste time trying to decipher hopelessly complex or broken code. It sees the code as it is. A web crawler simulation tool adopts this stricter, more literal perspective. It shows you the problems your browser is kindly hiding from you, revealing the technical debt that could be silently killing your SEO performance.
## The Core Benefits: Why Every SEO Needs a Crawler Emulator
Using a website crawling simulation tool isn't just a niche trick for technical SEO nerds. It's a fundamental practice that delivers tangible benefits for anyone serious about their online presence. It bridges the gap between how you think your site is structured and how search engines actually perceive it. This alignment is the key to sustainable, long-term search visibility. The insights gained from a single simulated crawl can inform your content strategy, your technical roadmap, and your overall digital marketing efforts for months to come.
From identifying show-stopping errors that prevent your pages from ever being seen by Google, to fine-tuning the efficiency of how Google explores your site, the benefits are numerous. It's about moving from a reactive to a proactive SEO stance. Instead of waiting for rankings to drop and then trying to figure out why, you can use a simulator to spot potential issues long before they impact your traffic and revenue. It is, without a doubt, one of the highest-leverage activities in a modern SEO's toolkit.
### Uncovering Critical Crawlability Issues
Crawlability refers to a search engine's ability to access and crawl the content on your website. If a spider can't crawl your pages, it can't index them, and if it can't index them, they will never rank. It's the first and most critical hurdle. A spider simulator is the ultimate tool for diagnosing these issues. It will immediately flag "orphan pages" – pages that have no internal links pointing to them, making them invisible to crawlers navigating your site. It will also pinpoint broken links (404 errors) that lead spiders to dead ends, wasting their time and preventing them from discovering further content.
Furthermore, a crawler emulator helps you audit your robots.txt file. This simple text file is a set of instructions for bots, but a tiny mistake—a misplaced slash or an overly broad "Disallow" directive—can accidentally block search engines from accessing entire sections of your site. The simulator will show you exactly which pages are being blocked and why. It helps you find and fix these fundamental barriers, ensuring that every important page on your site is open for business when the spiders come knocking.
### Diagnosing Indexation Problems
Okay, so a spider can crawl your site. That's great, but it's only half the battle. The next step is indexation—the process of being added to the search engine's massive database. Many things can go wrong here. A common culprit is the "noindex" meta tag. This is a specific instruction in your page's code that tells a spider, "You can crawl this page, but don't add it to your index." While useful for private pages or login areas, it's often accidentally left on important pages after a site redesign, effectively making them invisible to search. A spider simulator will list every page that has a "noindex" tag, allowing you to spot these errors in seconds.
Another key area is the use of canonical tags (rel="canonical"). These tags tell search engines which version of a page is the "master" copy when duplicate or highly similar content exists. Misconfiguring these can lead to the wrong page being indexed, or valuable link equity being split across multiple URLs. A simulator provides a bird's-eye view of all your canonical tags, letting you ensure they are pointing to the correct pages and consolidating your SEO power effectively.
### Optimizing Your Precious Crawl Budget
Crawl budget is a term that refers to the number of pages and the frequency with which search engine spiders will crawl a website. It's not an infinite resource. Spiders allocate a finite amount of attention to each site based on factors like its size, authority, and health. If you waste this budget, important pages might not get crawled and updated as frequently as they should. A SEARCH ENGINE SPIDER SIMULATOR is your best friend for crawl budget optimization.
How does it help? First, it identifies redirect chains. A link that goes from Page A -> Page B -> Page C before landing on the final destination forces a spider to make multiple requests, eating up the budget. A simulator flags these so you can fix the original link to point directly to Page C. It also helps you find and "nofollow" links to unimportant pages (like login pages or endless calendar archives) that don't need to be crawled, preserving the budget for your money-making content. By streamlining the crawler's path through your site, you ensure your most valuable pages get the attention they deserve.
## How to Use a Spider Simulator: A Step-by-Step Guide
Getting started with a website crawling simulation tool can seem intimidating, but the basic process is surprisingly straightforward. The beauty of these tools is that they do the heavy lifting for you. Your job is to initiate the crawl and then interpret the results. Think of it like ordering a blood test: the lab (the simulator) runs the complex analysis, and your job, with the help of a doctor (or this guide), is to understand the report.
The initial setup usually takes just a few minutes, but the insights you can gain are profound. We'll walk through the essential steps, from selecting the right tool for your needs to running your very first crawl and making sense of the initial wave of data. Don't worry about understanding everything at once. The goal of your first crawl is to get a baseline understanding of your site's technical health.
### Step 1: Choosing Your Tool (Free vs. Paid)
The market is filled with excellent web crawler emulators, each with its own strengths. They generally fall into two categories: free and paid. For beginners or those with smaller websites, a free tool is a fantastic starting point. It will give you access to all the core data points like status codes, page titles, and meta descriptions. In fact, you can get started right now with a powerful, 100% free SEARCH ENGINE SPIDER SIMULATOR that runs directly in your browser without any complex installation. It's a perfect way to dip your toes in the water.
Paid tools, such as Screaming Frog SEO Spider or Sitebulb, are typically desktop applications that offer more advanced features. These include the ability to crawl massive websites (millions of pages), render JavaScript, integrate with APIs like Google Analytics and Search Console, and generate highly detailed, customizable reports. For professional SEOs, agencies, or large in-house teams, the investment in a paid tool is often non-negotiable. But for the vast majority of users, starting with a robust free option is the smartest move.
### Step 2: Running Your First Crawl Simulation
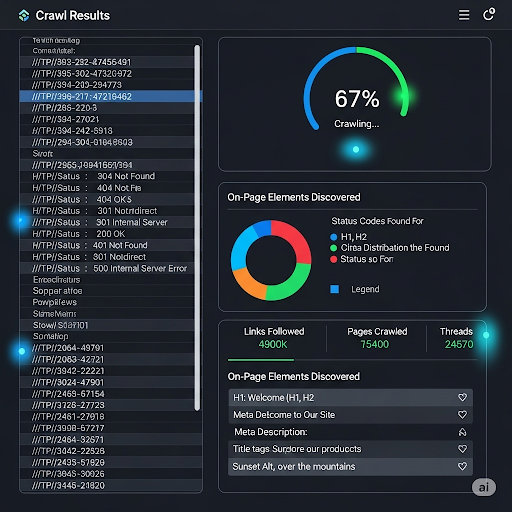
Once you've chosen your tool, running a crawl is as simple as entering your website's homepage URL into the main input field and hitting "Start" or "Crawl." The simulator will begin its work, starting from your homepage and following every internal link it can find, just like Googlebot would. You'll see a live feed of URLs being discovered and analyzed. For a small site, this might take a few minutes. For a very large site, it could take several hours.
During this process, the tool is building a comprehensive picture of your site's architecture. It's requesting each URL, recording the server's response (the HTTP status code), parsing the HTML of the page, and extracting key elements. It's looking for <title> tags, meta description tags, <h1> tags, <img> tags and their alt text, canonical tags, and of course, all the <a> (link) tags to find new pages to add to its queue. Be patient and let the process complete fully to ensure you have a complete data set to work with.
### Step 3: Analyzing the Key Data Points
When the crawl is finished, you'll be presented with a large table of data, with each row representing a URL found on your site. This can look overwhelming at first, so it's important to know where to focus your attention initially. Don't try to analyze everything at once. Start with the big-picture items that have the largest potential impact.
First, filter your results by HTTP status code. Look for any 4xx errors (like 404 Not Found), as these represent broken links that need to be fixed. Next, look for any 5xx server errors, which indicate serious problems with your hosting. After that, scan for redirect chains (301s that point to other 301s). Then, move on to on-page elements. Are any of your important pages missing a <title> tag or a meta description? Do you have duplicate page titles across your site? Tackling these high-level issues first will provide the biggest and most immediate SEO improvements.
## Deconstructing the Simulator's Report: What to Look For
A spider simulator's report is a treasure map leading to SEO gold, but only if you know how to read it. The raw data can be dense, but it's organized into columns that correspond to specific, crucial elements of your web pages. Learning to navigate these columns and understand what they represent is the skill that separates amateur SEOs from seasoned professionals. It’s about translating raw data into actionable insights.
We will now break down some of the most important sections of a typical crawl report. We'll focus on the low-hanging fruit—the areas where you can find quick wins and fix problems that are actively harming your site's performance in search. Mastering these few key areas will put you light-years ahead of competitors who are only focusing on keywords and content without considering the technical foundation.
### Mastering HTTP Status Codes (200, 301, 404, 5xx)
HTTP status codes are three-digit numbers that a web server sends back to a browser or spider when it requests a URL. They are a fundamental language of the web, and understanding them is non-negotiable. The spider simulator will have a dedicated column for this.
200 OK: This is the best-case scenario. It means the page was found and delivered successfully.
301 Moved Permanently: This is a redirect. It tells the spider the page has moved to a new location. While necessary, you want to avoid chains of redirects (one redirect pointing to another). The simulator helps you find these so you can update the original link.
404 Not Found: This is a dead end. The requested URL doesn't exist. These are bad for user experience and waste crawl budget. You should find where the broken link is and either fix it or redirect the broken URL to a relevant page.
5xx Server Error: This is a critical problem. It means your server failed to fulfill the request. If a spider sees this, it will likely leave and come back later. Consistent 5xx errors can lead to de-indexing and are a red flag that your hosting needs immediate attention.
### Scrutinizing Page Titles and Meta Descriptions
Page titles (<title> tag) and meta descriptions are your primary advertising space on the Google search results page. They are critically important for both SEO and click-through rate (CTR). A spider simulator makes auditing them across your entire site a breeze. You can instantly see:
Missing Titles/Descriptions: Pages that are missing these essential tags. This is a huge missed opportunity and should be fixed immediately.
Duplicate Titles/Descriptions: When multiple pages have the same title or description, it can confuse search engines about which page is the most relevant for a given topic. Each important page should have a unique, descriptive title.
Length Issues: The simulator will show you the character or pixel length of your titles and descriptions. If they are too long, they will be truncated in the search results. If they are too short, you're not making full use of the space to entice users to click. You can quickly identify all the tags that need to be rewritten for optimal length.
### Auditing Your Internal Linking Structure
Internal links are the hyperlinks that connect one page on your website to another. They are the pathways that both users and search engine spiders use to navigate your site. A strong internal linking structure helps distribute "link equity" (or "PageRank") throughout your site, signaling to Google which of your pages are most important. A crawler emulator is the best tool for this job.
You can analyze the "inlinks" to any given page, seeing exactly which other pages on your site are linking to it. Is your most important service page only getting one internal link from an obscure blog post? That's a problem. The simulator helps you identify these "deep" pages that are many clicks away from the homepage, making them harder for spiders to find and deem important. You can then strategically add internal links from more authoritative pages (like your homepage or main service pages) to boost the visibility of your key content. It’s like building highways to your most important destinations.
## The JavaScript Conundrum: Simulating a Modern Web
The web has evolved. Many modern websites are no longer simple, static HTML documents. They are dynamic applications built with JavaScript frameworks like React, Angular, or Vue.js. This presents a unique challenge for search engines. Initially, spiders could only read the raw HTML source code. If your content was loaded by JavaScript after the initial page load, the spider would simply see a blank page. This was a massive SEO problem.
While Googlebot has become incredibly sophisticated and can now render JavaScript to see the final page much like a browser (this is called Client-Side Rendering or CSR), it's not a perfect process. It's also more resource-intensive for Google, which can impact your crawl budget. This is why understanding the difference between the initial HTML and the final, rendered page is more important than ever. Advanced spider simulators have risen to this challenge, offering features to specifically diagnose JavaScript-related SEO issues.
### How Spiders Handle JavaScript Rendering
When Googlebot encounters a page that relies heavily on JavaScript, it typically performs a two-wave indexing process. In the first wave, it crawls the raw HTML, just as it always has. It indexes any content it can find there immediately. Then, if it detects that JavaScript is needed to see the full content, the page is put into a queue for rendering. In the second wave, a service called the Web Rendering Service (WRS), which is based on a recent version of Chrome, executes the JavaScript and renders the full page. The spider then crawls this final, rendered version.
The problem is that there can be a delay—sometimes days or even weeks—between the first and second waves. If your most important content is only visible after rendering, it won't be indexed as quickly. Furthermore, errors in your JavaScript code can prevent the WRS from rendering the page correctly, meaning your content may never be seen at all. This is why it's crucial to ensure your most critical content and links are present in the initial HTML source whenever possible (a technique known as Server-Side Rendering or SSR).
### Comparing the Raw HTML vs. the Rendered DOM
This is where a premium SEARCH ENGINE SPIDER SIMULATOR truly shines. Advanced tools like Screaming Frog allow you to switch the crawl mode from "Text Only" to "JavaScript." In JavaScript mode, the tool won't just download the HTML; it will actually render the page using a built-in Chromium browser, just like Google's WRS. It then allows you to directly compare the two versions.
You can run a crawl and ask the simulator: "Show me the difference between the raw HTML and the final rendered HTML (the Document Object Model, or DOM)." The tool will highlight any content or links that only appear after rendering. This is an incredibly powerful diagnostic feature. With it, you can instantly see if your main navigation, your key product descriptions, or your internal links are dependent on client-side JavaScript. If they are, you have identified a potential point of failure and can work with your developers to move that critical content into the initial HTML response for faster, more reliable indexing.
## Advanced Simulation Techniques for Pro SEOs
Once you've mastered the basics of checking status codes and auditing your on-page elements, you can start leveraging a spider simulator for more advanced and nuanced technical SEO tasks. These techniques allow you to get incredibly granular with your analysis, testing specific scenarios and ensuring that your site is perfectly optimized for every type of bot and every potential crawl scenario. This is where you can gain a real competitive advantage.
These advanced features move beyond a simple "what does the spider see?" to answer more complex questions like "what does the spider see when it pretends to be a mobile phone?" or "am I correctly telling the spider which pages to ignore?" This level of control allows you to preemptively solve problems and build a technically flawless website that search engines will love to crawl and reward with higher rankings. It's about fine-tuning the engine for peak performance.
### Simulating Different User-Agents (Desktop vs. Mobile)
A "user-agent" is a string of text that a browser or spider sends to a web server to identify itself. For example, Googlebot identifies itself with a Googlebot user-agent string. In today's world of mobile-first indexing, Google primarily crawls and indexes the web using its Googlebot-Mobile user-agent. This means that what Google sees on its "smartphone" is what it considers to be the primary version of your site for ranking purposes.
A powerful crawler emulator allows you to change the user-agent before you start a crawl. You can run one crawl using the default desktop user-agent, and then run a second crawl using the Googlebot-Mobile user-agent. By comparing the two crawls, you can uncover critical differences. Does your site show different content to mobile users? Are the internal links different? Is a crucial piece of content missing from the mobile version? This technique is essential for ensuring your site is truly optimized for the mobile-first world and that you are not accidentally hiding important information from Google's primary crawler.
### Testing Your robots.txt and Meta Robots Directives
The robots.txt file and meta robots tags are your primary tools for communicating with search engine spiders. They are the rules of the road for your website. A robots.txt file can block access to entire folders, while a meta robots tag on a specific page can give instructions like noindex (don't add to the search index) or nofollow (don't follow any links on this page). However, it's easy to make a mistake.
A sophisticated SEARCH ENGINE SPIDER SIMULATOR lets you test these rules with precision. You can configure the simulator to obey your robots.txt file, and it will report back exactly which URLs it was blocked from crawling. More advanced features allow you to override these rules. For example, you can tell the simulator to "Ignore robots.txt" to crawl pages that should be blocked, just to see what's in there. You can also test changes to your robots.txt file in the simulator's settings before you upload them to your live site, preventing costly mistakes that could take your entire site out of the search results.
## Beyond the Simulator: Integrating with Other Tools
A search engine spider simulator is an incredibly powerful tool, but it doesn't exist in a vacuum. To get a truly holistic view of your website's performance and health, you need to combine the insights from your crawl simulation with data from other essential SEO tools. By cross-referencing information from different sources, you can connect the dots between technical issues and their real-world impact on rankings and traffic.
Think of the spider simulator as the X-ray machine. It shows you the bone structure. Other tools, like Google Search Console, are like the patient's chart, showing you symptoms and historical data. Log file analysis is like having a security camera in the building, showing you who actually came in and when. When you use all three together, you move from being a technician to being a master diagnostician, able to pinpoint the exact cause of any SEO issue.
### Combining Simulator Data with Google Search Console
Google Search Console (GSC) is a free service from Google that gives you a wealth of information about how Google itself sees your site. It tells you which keywords you rank for, which pages are indexed, and it reports on crawl errors it has encountered. The synergy between a simulator and GSC is immense. For example, GSC might report a spike in "Not Found (404)" errors in its Coverage report. But it won't always tell you where the broken links are located on your site.
That's where you fire up your spider simulator. You can take the list of 404 URLs from GSC, plug them into your crawler tool's analysis feature, and it will tell you the exact source pages on your site that contain the broken links to those URLs. You've just gone from knowing what the problem is to knowing how to fix it. Similarly, if GSC says a page is "Discovered - currently not indexed," you can crawl that specific URL in your simulator to check for a stray "noindex" tag or other technical blockers.
### Cross-Referencing with Log File Analysis
For the ultimate in technical SEO analysis, professionals turn to log file analysis. Every time any visitor—human or bot—requests a file from your web server, a line is written to a log file. These files are a raw, unfiltered record of all traffic to your site. By analyzing these logs, you can see exactly how often Googlebot is visiting, which pages it's crawling most frequently, and how much of your crawl budget it's consuming.
This is where you validate the findings of your SEARCH ENGINE SPIDER SIMULATOR. Your simulator might show you a clean, efficient site structure. But the log files will tell you if Googlebot is actually crawling it that way. Are there sections of your site that Googlebot rarely or never visits, despite them being crawlable? This could indicate a lack of internal linking or perceived importance. Are bots spending too much time crawling URLs with parameters that you thought were blocked? The log files provide the ground truth, allowing you to confirm your hypotheses from the simulation and measure the real-world impact of your technical fixes. This combination, as explained by resources like the Wikipedia page on Web crawlers, is the pinnacle of technical SEO.
Conclusion
In the complex and ever-shifting world of search engine optimization, having a clear view of your website's foundation is not just an advantage; it's a necessity. A SEARCH ENGINE SPIDER SIMULATOR provides this clarity. It empowers you to step into the "shoes" of a search engine crawler, to see your digital property not as a human user does, but as the very bots that determine your online visibility do. This perspective shift is the key to unlocking a new level of control over your SEO destiny.
From diagnosing critical crawlability and indexation errors to optimizing your crawl budget and mastering the complexities of JavaScript rendering, a crawler emulator is your all-in-one technical diagnostic tool. It transforms SEO from a guessing game into a data-driven science. By regularly crawling your own site, analyzing the reports, and taking action on the insights, you build a healthier, more efficient, and more authoritative website—one that is perfectly primed to earn the top rankings it deserves.
## Frequently Asked Questions (FAQs)
1. What is the main difference between a spider simulator and Google Search Console? A spider simulator actively crawls your site on-demand to show you its current state and structure. Google Search Console (GSC) provides data from Google's past crawls, showing you what Google has already found. The simulator is a proactive diagnostic tool for finding issues now, while GSC is a reactive reporting tool for understanding historical performance and errors Google has logged.
2. Can a search engine spider simulator predict my website's rankings? No. A simulator is a technical SEO tool, not a ranking predictor. It helps you find and fix technical issues that prevent you from ranking well. High rankings depend on many other factors, including content quality, backlinks, and user experience. The simulator ensures your site has a solid technical foundation, which is a prerequisite for ranking, but it doesn't guarantee it.
3. How often should I run a crawl simulation on my website? For most websites, running a full crawl once a month is a good practice to catch any new issues. For very large, dynamic sites (like e-commerce or news sites) that change daily, running a crawl weekly might be more appropriate. It's also essential to run a crawl after any major site changes, such as a redesign, migration, or significant content update.
4. Are free spider simulators powerful enough for real SEO work? Absolutely. For small to medium-sized websites, a high-quality free spider simulator provides all the essential features needed to diagnose the most common and critical technical SEO issues. They are an excellent way to audit status codes, page titles, internal links, and more. Paid tools become necessary for very large sites or for advanced features like JavaScript rendering and API integrations.
5. Does a spider simulator "see" images and videos like a human? No, and this is a key concept. A simulator does not "see" the visual content of an image or video. It "sees" the code associated with it. For an image, it will see the file name (e.g., blue-widget.jpg) and, most importantly, the alt text. For a video, it will see the embed code and any associated structured data. It's a reminder to always use descriptive file names and alt text so spiders can understand what the media is about.
6. Can running a spider simulator harm my website or server? It's possible, but unlikely for most modern servers. A simulator makes many rapid requests to your server, which can increase the load. On very cheap or poorly configured hosting, an aggressive crawl could theoretically slow the site down temporarily. Most simulators have speed settings that allow you to limit the number of requests per second to be gentle on your server. For a standard website on decent hosting, it's perfectly safe.